Advanced Langgraph: Deep dive into open deep research
Analyzing the code from the public open deep research project from the langchain team to research information online using tools and llms.
What is Open deep research
Open deep research, made by the langchain team does something similar to perplexity but the research results from are a bit more thorough. Is a good project to analyse and learn how the team behind langgraph uses it.
To better follow the guide I recommend to download the github repo and see in detail all the pieces of code: https://github.com/langchain-ai/open_deep_research
To follow this guide with the same working version you can go to this commit, https://github.com/langchain-ai/open_deep_research/tree/26f163757dd2ed1a284a1a2c112021d25220f107
Configuration and other general utils
In this section I’ll explain how they define the configuration and use it in every node, these is not specific to this project, it just a way to define this config in just one place and then reuse it everywhere.
This is how the class Configuration is defined, this sets the defaults for many fields, these defaults can be overwritten when initialising the graph.
class Configuration(BaseModel):
"""Main configuration class for the Deep Research agent."""
# General Configuration
max_structured_output_retries: int = Field(
default=3,
metadata={
"x_oap_ui_config": {
"type": "number",
"default": 3,
"min": 1,
"max": 10,
"description": "Maximum number of retries for structured output calls from models"
}
}
)
# ... and much more fields
@classmethod
def from_runnable_config(
cls, config: Optional[RunnableConfig] = None
) -> "Configuration":
"""Create a Configuration instance from a RunnableConfig."""
configurable = config.get("configurable", {}) if config else {}
field_names = list(cls.model_fields.keys())
values: dict[str, Any] = {
field_name: os.environ.get(field_name.upper(), configurable.get(field_name))
for field_name in field_names
}
return cls(**{k: v for k, v in values.items() if v is not None})
Here below there is an example of how this configuration is initialised in every node, sometimes they use different models depending on the purpose of the node, like final_report_model or research_model.
async def some_node(state: SomeGraph, config: RunnableConfig) -> Command[Literal["some_node"]]:
configurable = Configuration.from_runnable_config(config)
research_model_config = {
"model": configurable.research_model, # default: openai:gpt-4.
"max_tokens": configurable.research_model_max_tokens, # default: 10000
"api_key": get_api_key_for_model(configurable.research_model, config),
"tags": ["langsmith:nostream"]
}
This research_model_config is the passed on to the llm instance. They initialise the init_chat_model , init_chat_model is a more flexible way to initialise an llm instance than to importing the provider-specific instantiation from langchain.
configurable_model = init_chat_model(
configurable_fields=("model", "max_tokens", "api_key"),
)
research_model = (
configurable_model
.with_config(research_model_config)
)
Graph Structure
This is how the main graph structure looks like it’s pretty simple but there is more complex subgraphs inside the nodes, in the following sections we’re gonna go over each node and see what it does, we can see the attributes inside the class, this will be used alonsgside the whole graph to communicate nodes with each other. The most important here are supervisor_messages and final_report. We’ll see in the following sections how each of these is used
class AgentState(MessagesState):
"""Main agent state containing messages and research data."""
supervisor_messages: Annotated[list[MessageLikeRepresentation], override_reducer]
research_brief: Optional[str]
raw_notes: Annotated[list[str], override_reducer] = []
notes: Annotated[list[str], override_reducer] = []
final_report: str
Let’s see which type the user for the supervisor_messages attribute, override_reducer
def override_reducer(current_value, new_value):
"""Reducer function that allows overriding values in state."""
if isinstance(new_value, dict) and new_value.get("type") == "override":
return new_value.get("value", new_value)
else:
return operator.add(current_value, new_value)
# Example
current_value = ['Hello, how can I assist you today?', "I'm doing great, thanks for asking!"]
state = override_reducer(state, {"type": "override", "value": [HumanMessage(content="Reset conversation.")]})
current_value = ['Hello, how can I assist you today?']
state = override_reducer(state, [HumanMessage(content="New Message.")]})
current_value = ['Hello, how can I assist you today?', "New Message."]
And this is implemented in the deep_researcher_builder
deep_researcher_builder = StateGraph(
AgentState,
input=AgentInputState,
config_schema=Configuration
)
# Add main workflow nodes for the complete research process
deep_researcher_builder.add_node("clarify_with_user", clarify_with_user)
deep_researcher_builder.add_node("write_research_brief", write_research_brief)
deep_researcher_builder.add_node("research_supervisor", supervisor_subgraph)
deep_researcher_builder.add_node("final_report_generation", final_report_generation)
# Define main workflow edges for sequential execution
deep_researcher_builder.add_edge(START, "clarify_with_user")
deep_researcher_builder.add_edge("research_supervisor", "final_report_generation")
deep_researcher_builder.add_edge("final_report_generation", END)
# Compile the complete deep researcher workflow
deep_researcher = deep_researcher_builder.compile()
This is how the complete graph looks like, as we can see the parent graph just include 4 nodes, and one of this is the subgraph research_supervisor , which handles the main logic of the research.
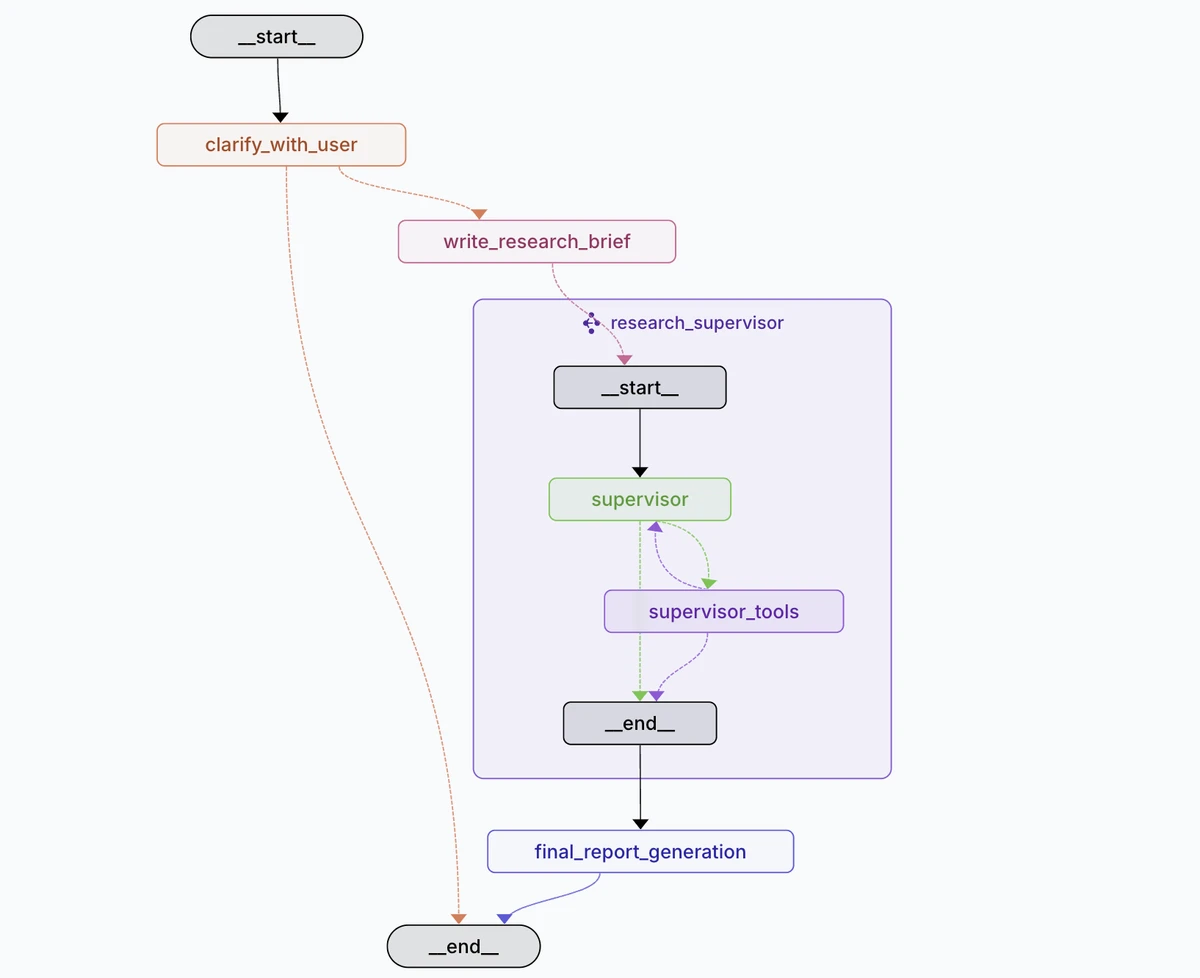
Part 1: Preparing the messages for the Research Supervisor Subgraph
This includes talking back to the user to specify details about the initial prompt and preparing the messages that will be used in the subgraph
clarify_with_user
This node is needed in case the user asks something in a vague way, like. “I want to go to a gym” — Where? What do you want to train? …
The clarification model is the llm instance, that has the structured output of the class ClarifyWithUser to get the exact information for the user request.
clarification_model = (
init_chat_model(
configurable_fields=("model", "max_tokens", "api_key"),
)
.with_structured_output(ClarifyWithUser)
.with_retry(stop_after_attempt=configurable.max_structured_output_retries)
.with_config(model_config)
)
The ClarifyWithUser has three main attributes, need_clarification, question and verification.
class ClarifyWithUser(BaseModel):
need_clarification: bool = Field(
description="Whether the user needs to be asked a clarifying question.",
)
question: str = Field(
description="A question to ask the user to clarify the report scope",
)
verification: str = Field(
description="Verify message that we will start research after the user has provided the necessary information.",
)
The clarify_with_user_instructions is a prompt that will return an object with the attributes from ClarifyWithUser.
In the prompt is interesting to see that the three parameters from the class ClarifyWithUser are written again and given more details for each.
The most interesting part is how they define in the prompt that the question or the verification variable should be empty or not.
# EXTRACT FROM THE PROMPT clarify_with_user_instructions
If you need to ask a clarifying question, return:
"need_clarification": true,
"question": "<your clarifying question>",
"verification": ""
If you do not need to ask a clarifying question, return:
"need_clarification": false,
"question": "",
"verification": "<acknowledgement message that you will now start research based on the provided information>"
In this example below, when the Command goes to END, the graph ends to allow the user to answer the question.
If it does not need clarification it continues to the next node, write_research_brief , which is actually defined in the graph but not included in the edges. This way with Commands of handling the conditional continuation of the graph is more intuitive and easier to see than with conditional_edges.
get_buffer_string: "Convert a sequence of Messages to strings and concatenate them into one string"
Command: "This is a tool from langgraph that allows us to specify to the next node we want to go"
# Step 3: Analyze whether clarification is needed
prompt_content = clarify_with_user_instructions.format(
messages=get_buffer_string(messages),
date=get_today_str()
)
response = await clarification_model.ainvoke([HumanMessage(content=prompt_content)])
# Step 4: Route based on clarification analysis
if response.need_clarification:
# End with clarifying question for user
return Command(
goto=END,
update={"messages": [AIMessage(content=response.question)]}
)
else:
# Proceed to research with verification message
return Command(
goto="write_research_brief",
update={"messages": [AIMessage(content=response.verification)]}
)
Example output. We can see how the answer from the prompt are used on each case.
human message 1: "is there any open mats to train bjj in new york"
AI message 1 (response.question): "Could you clarify whether you are looking for open mats in all of New York State, or specifically in New York City? Also, do you prefer gi, no-gi, or are you open to both types of BJJ training?"
# here the graph pipeline finalizes and is restarted when the user adds another message
human message 2: "In new york city, I prefer nogi"
AI message 2 (response.verification ): "Thank you for the clarification. You are looking for open mats to train no-gi Brazilian Jiu-Jitsu in New York City. I now have enough information to begin researching suitable options for you."
write_research_brief
The objective of this node is to generate a guide that will guide the “research supervisor” (the next node/subgraph). The final output will be two messages, one system prompt and one human prompt.
Like before, this research_model is mainly the llm alongside a couple of options like withStructuredOptions with the class ResearchQuestion.
class ResearchQuestion(BaseModel):
"""Research question and brief for guiding research."""
research_brief: str = Field(
description="A research question that will be used to guide the research.",
)
research_model = (
configurable_model
.with_structured_output(ResearchQuestion)
.with_retry(stop_after_attempt=configurable.max_structured_output_retries)
.with_config(research_model_config)
)
This research model is used for the transform_messages_into_research_topic_prompt , this is a prompt to understand better what is what the user wants to research.
prompt_content = transform_messages_into_research_topic_prompt.format(
messages=get_buffer_string(state.get("messages", [])),
date=get_today_str()
)
response = await research_model.ainvoke([HumanMessage(content=prompt_content)])
The other prompt is the system_prompt, to define some rules for the AI when searching information.
supervisor_system_prompt = lead_researcher_prompt.format(
date=get_today_str(),
max_concurrent_research_units=configurable.max_concurrent_research_units,
max_researcher_iterations=configurable.max_researcher_iterations
)
On the lead_researcher_prompt , there are some interesting concepts used. Each part of the prompt is compressed between tags like
<Task>: "Defines the task"
<Available Tools>: "Specifies which tools are available for the research"
<Instructions>: "Steps for the AI to process the information that the user needs."
<Hard Limits>: "Used to prevent excessive delegation, to avoid the number of calls made to the tools."
<Show Your Thinking>: "Specifies already a lot of detailed logic, like what to do after using certain tools and which tools need to use in every case."
<Scaling Rules>: "How to structure the question into one or multiple sub agents. "
Here there is a snippet of the available tools, remarcable that here there is already some logic of how the tools should be used and in which order.
<Available Tools>
You have access to three main tools:
1. **ConductResearch**: Delegate research tasks to specialized sub-agents
2. **ResearchComplete**: Indicate that research is complete
3. **think_tool**: For reflection and strategic planning during research
**CRITICAL: Use think_tool before calling ConductResearch to plan your approach, and after each ConductResearch to assess progress. Do not call think_tool with any other tools in parallel.**
</Available Tools>
Finally this node is ended with a single Command that continues the graph to the following node, research_supervisor. Look at how the type override is used to reset the entire list supervisor_messages .
return Command(
goto="research_supervisor",
update={
"research_brief": response.research_brief,
"supervisor_messages": {
"type": "override", # The whole supervisor_messages are overwritten with just these two
"value": [
SystemMessage(content=supervisor_system_prompt),
HumanMessage(content=response.research_brief)
]
}
}
)
Example output of the research brief. The system prompt will be always the same.
response.research_brief : "I want to find open mats in New York City where I can train no-gi Brazilian Jiu-Jitsu. Please identify current (as of August 2025) locations, academies, or gyms that offer no-gi BJJ open mats in NYC. Include details such as schedule (days and times), location/address, drop-in or membership requirements (if available), and any costs or prerequisites. If possible, prioritize information from official gym websites or social media, and list multiple options covering all five boroughs if relevant. I am open to any schedules, locations, and price ranges, but I specifically do not want gi/open mat options—please focus only on no-gi training."
Part 2: Subgraph - research_supervisor
Here is the main logic of the whole project. The initial input are just the two messages defined in the previous node, the system message with the detailed instructions of how to work with the tools and more and the research topic that the user wants to research about.
As it was previously defined in the parent graph (deep_researcher_builder)
deep_researcher_builder.add_node("research_supervisor", supervisor_subgraph)
We can see that many attributes from the class SupervisorState are the same as the ones from the parent graph. The only difference is here the is the research_iterations instead of the final_report.
class SupervisorState(TypedDict):
"""State for the supervisor that manages research tasks."""
supervisor_messages: Annotated[list[MessageLikeRepresentation], override_reducer]
research_brief: str
notes: Annotated[list[str], override_reducer] = []
research_iterations: int = 0
raw_notes: Annotated[list[str], override_reducer] = []
We can see how these nodes are defined and how there is just one simple initialisation of the whole graph but no more edges, as this logic will be handled with Command in each node.
# Supervisor Subgraph Construction
supervisor_builder = StateGraph(SupervisorState, config_schema=Configuration)
supervisor_builder.add_node("supervisor", supervisor)
supervisor_builder.add_node("supervisor_tools", supervisor_tools)
supervisor_builder.add_edge(START, "supervisor")
supervisor_subgraph = supervisor_builder.compile()
supervisor
This is the node in charge of delegating the tasks to the different tools.
tools
Let’s take first a look at the tools used in this supervisor node.
Here we can see that the think tool doesn’t have any logic, we are just interested in the argument that is generated when creating the tool_call.
class ConductResearch(BaseModel):
"""Call this tool to conduct research on a specific topic."""
research_topic: str = Field(
description="The topic to research. Should be a single topic, and should be described in high detail (at least a paragraph).",
)
class ResearchComplete(BaseModel):
"""Call this tool to indicate that the research is complete."""
@tool(description="Strategic reflection tool for research planning")
def think_tool(reflection: str) -> str:
"""...Details about what the argument reflection should be..."""
return f"Reflection recorded: {reflection}"
First they define the tools and create the llm instance called research_model
# Available tools: research delegation, completion signaling, and strategic thinking
lead_researcher_tools = [ConductResearch, ResearchComplete, think_tool]
# Configure model with tools, retry logic, and model settings
research_model = (
configurable_model
.bind_tools(lead_researcher_tools)
.with_retry(stop_after_attempt=configurable.max_structured_output_retries)
.with_config(research_model_config)
)
The research_model defined in the beginning of the supervisor is then invoked with the supervisor_messages defined in write_research_brief which include the system prompt and the user prompt.
supervisor_messages = state.get("supervisor_messages", [])
response = await research_model.ainvoke(supervisor_messages)
The response is then forwarded to supervisor_tools using Command. Because the response doesn’t have the type override, the response will be added to the current supervisor_messages list.
return Command(
goto="supervisor_tools",
update={
"supervisor_messages": [response],
"research_iterations": state.get("research_iterations", 0) + 1
}
)
Supervisor (First iteration: think_tool)
In this execution, the think_tool will be picked in the first iteration.
Example output: This new object added in the supervisor_messages has the attribute tool_calls, which points to the think_tool with the reflection argument assigned by the llm.
{
...some arguments
"tool_calls": [
{
"name": "think_tool",
"args": {
"reflection": "The user's request is detailed but focused: they want information about no-gi Brazilian Jiu-Jitsu open mats in New York City for August 2025. The user wants current open mats (no gi only), with details on schedule, address, drop-in rules, costs, and prerequisites. They prioritize official sources and a diverse list covering all five boroughs if possible. The topic can be handled by a single agent due to its unified focus, though care must be taken to source current, reliable, and broad information from official webpages and social media."
},
"id": "call_0j5IFO7EUo1tdIqUJ0qvkKbf",
"type": "tool_call"
}
],
...more arguments
}
supervisor_tools
This node is used to execute the tools defined in the previous graph. There are multiple calls that go back and forth between this and the
Check exit conditions
First we see if it should continue using tools, we see that if the number of iterations or if there is no calls the graph ends or the supervisor though that the research is already complete.
exceeded_allowed_iterations = research_iterations > configurable.max_researcher_iterations
no_tool_calls = not most_recent_message.tool_calls
research_complete_tool_call = any(
tool_call["name"] == "ResearchComplete"
for tool_call in most_recent_message.tool_calls
)
if exceeded_allowed_iterations or no_tool_calls or research_complete_tool_call:
return Command(
goto=END,
update={
"notes": get_notes_from_tool_calls(supervisor_messages),
"research_brief": state.get("research_brief", "")
}
)
supervisor_tools (First iteration: think_tool)
A continuation we check if the last message of the supervisor_messages list has a any tool of type think_tool . The think_tool is not called, the argument reflection is extracted and added to all_tool_messages .
# Handle think_tool calls (strategic reflection)
think_tool_calls = [
tool_call for tool_call in most_recent_message.tool_calls
if tool_call["name"] == "think_tool"
]
for tool_call in think_tool_calls:
reflection_content = tool_call["args"]["reflection"]
all_tool_messages.append(ToolMessage(
content=f"Reflection recorded: {reflection_content}",
name="think_tool",
tool_call_id=tool_call["id"]
))
When all think_tool_calls are made, the execution goes back to the supervisor node. All the tool messages are assigned to the supervisor_messages .
update_payload["supervisor_messages"] = all_tool_messages
return Command(
goto="supervisor",
update=update_payload
)
A new message of type “tool” is added to the supervisor_messages
{
"content": "Reflection recorded: The user's request is detailed but focused: they want information about no-gi Brazilian Jiu-Jitsu open mats in New York City for August 2025. The user wants current open mats (no gi only), with details on schedule, address, drop-in rules, costs, and prerequisites. They prioritize official sources and a diverse list covering all five boroughs if possible. The topic can be handled by a single agent due to its unified focus, though care must be taken to source current, reliable, and broad information from official webpages and social media.",
type: "tool",
"name": "think_tool",
...other attributes
}
Supervisor (Second iteration: conduct_research)
As before, a call to the llm with the binded tools is done with all the messages.
response = await research_model.ainvoke(supervisor_messages)
In this iteration the tool picked has been conduct_research
{
...some arguments
"tool_calls": [
{
"name": "ConductResearch",
"args": {
"research_topic": "Identify and compile a list of current no-gi Brazilian Jiu-Jitsu open mat sessions taking place in New York City as of August 2025. Research should focus on obtaining information from official gym websites or gym social media accounts to ensure accuracy and up-to-date scheduling. For each open mat, provide the academy or gym name, schedule (days and times), location (address, borough), any membership or drop-in requirements and costs, as well as any prerequisites (e.g., skill level, waiver forms). Exclude gi or mixed gi/no-gi open mats—list only no-gi sessions. Include options from all five NYC boroughs if available, and strive to provide a diverse selection in terms of schedule, location, and price range."
},
"id": "call_6zYmcwGspmemeKYlQSjCdvkN",
"type": "tool_call"
}
],
...more arguments
}
supervisor_tools (second iteration: conduct_research)
When there is conduct_research another subgraphed is invoked, researcher_subgraph, this will be explained in the following section.
conduct_research_calls = [
tool_call for tool_call in most_recent_message.tool_calls
if tool_call["name"] == "ConductResearch"
]
allowed_conduct_research_calls = conduct_research_calls[:configurable.max_concurrent_research_units]
research_tasks = [
researcher_subgraph.ainvoke({
"researcher_messages": [
HumanMessage(content=tool_call["args"]["research_topic"])
],
"research_topic": tool_call["args"]["research_topic"]
}, config)
for tool_call in allowed_conduct_research_calls
]
tool_results = await asyncio.gather(*research_tasks)
Once all the results are gathered, they are added to all_tools_messages list, which will be processed again by the supervisor, and it will determine if the results are enough or not.
# Create tool messages with research results
for observation, tool_call in zip(tool_results, allowed_conduct_research_calls):
all_tool_messages.append(ToolMessage(
content=observation.get("compressed_research", "Error synthesizing research report: Maximum retries exceeded"),
name=tool_call["name"],
tool_call_id=tool_call["id"]
))
Example result: This is another message of type “tool” added to the supervisor_messages with what the research topic subgraph has been able to find.
{
"content": "** Findings** **Manhattan:** 10th Planet Jiu Jitsu NYC, Studio X Brazilian Jiu-Jitsu NYC ... .",
"type": "tool",
"name": "ConductResearch",
}
Also the attribute raw_notes of the SupervisorState is added to the update_payload, which will update the state afterwards.
raw_notes_concat = "\n".join([
"\n".join(observation.get("raw_notes", []))
for observation in tool_results
])
if raw_notes_concat:
update_payload["raw_notes"] = [raw_notes_concat]
Part 3: Subgraph - research_topic
Now we’ll take a look at how the observation objects with the attributes compressed_research and raw_notes are generated, both retrieved when processing a tool call of type conduct_research .
Let’s first take a look at how this was invoked in the previous section
researcher_subgraph.ainvoke({
"researcher_messages": [
HumanMessage(content=tool_call["args"]["research_topic"])
],
"research_topic": tool_call["args"]["research_topic"]
}, config)
We see that in the initial call, the researcher_messages and research_topic attributes are initialised.
class ResearcherState(TypedDict):
"""State for individual researchers conducting research."""
researcher_messages: Annotated[list[MessageLikeRepresentation], operator.add]
tool_call_iterations: int = 0
research_topic: str
compressed_research: str
raw_notes: Annotated[list[str], override_reducer] = []
We see there are three main nodes in the subgraph: researcher, researcher_tools and compress_research.
As before we see that the flow of the graph with just the edges does not make much sense, the logic between nodes is handled by Command
researcher_builder = StateGraph(
ResearcherState,
output=ResearcherOutputState,
config_schema=Configuration
)
# Add researcher nodes for research execution and compression
researcher_builder.add_node("researcher", researcher) # Main researcher logic
researcher_builder.add_node("researcher_tools", researcher_tools) # Tool execution handler
researcher_builder.add_node("compress_research", compress_research) # Research compression
# Define researcher workflow edges
researcher_builder.add_edge(START, "researcher") # Entry point to researcher
researcher_builder.add_edge("compress_research", END) # Exit point after compression
researcher
This node acts in a similar fashion as the supervisor from the previous graph, it defines the various tools available and determines which one should be called
tools = await get_all_tools(config)
# Step 2: Configure the researcher model with tools
research_model_config = {
"model": configurable.research_model,
"max_tokens": configurable.research_model_max_tokens,
"api_key": get_api_key_for_model(configurable.research_model, config),
"tags": ["langsmith:nostream"]
}
Similar as we’ve seen before the prompt is created and the tools are binded to the llm model.
researcher_prompt = research_system_prompt.format(
mcp_prompt=configurable.mcp_prompt or "",
date=get_today_str()
)
# Configure model with tools, retry logic, and settings
research_model = (
configurable_model
.bind_tools(tools)
.with_retry(stop_after_attempt=configurable.max_structured_output_retries)
.with_config(research_model_config)
)