Lessons Learned Building a Real-World AI Agent with LangGraph
A deep-dive tutorial on building a real-world AI agent with LangGraph. Learn key architectural patterns, state management techniques, and performance optimizations from the implementation of translateprompt.com
The board meeting was moved to Friday.
La reunión de consejo se ha movido al viernes.
La reunión directiva se ha movido al viernes.
Prepare the board meeting agenda.
Prepara la agenda de la reunión de consejo.
Prepara la agenda de la reunión directiva.
The board meeting was moved to Friday.
La reunión de consejo se ha movido al viernes.
La reunión directiva se ha movido al viernes.
Prepare the board meeting agenda.
Prepara la agenda de la reunión de consejo.
Prepara la agenda de la reunión directiva.
The board meeting was moved to Friday.
La reunión de consejo se ha movido al viernes.
La reunión directiva se ha movido al viernes.
Prepare the board meeting agenda.
Prepara la agenda de la reunión directiva.
If you’ve ever used an online translator, you know the routine. You paste your text, get a translation that’s about 95% right, and then you manually fix the last 5%, that one technical term, the company name, or a phrase that just doesn’t sound natural.
The next day, you translate something similar. The same mistake appears. You fix it. Again. This cycle is the core limitation of most translation tools: they don’t learn from you. They just perform a task.
TranslatePrompt is built to break that cycle. It’s a translator designed not just to be corrected, but to be taught.
Building an agent that can learn, remember, and interact over multiple turns is a complex challenge. In this article, I’ll share the architectural decisions, key learnings, and practical code patterns I discovered while building translateprompt.com using LangChain's powerful library for building stateful agents, LangGraph.
The Core Architecture: Why LangGraph?
A conversational, state-aware application requires more than a simple linear chain. The user might provide feedback, the agent might need to ask for clarification, or it might loop back on itself to refine its work. This cyclical, state-driven flow is a natural fit for a graph.
LangGraph allows you to define agent workflows as state machines. You define nodes (functions that do work) and edges (the logic that connects them). This was the perfect tool for translateprompt.com, which revolves around a simple but powerful loop: translate, get feedback, refine, and repeat.
The Agent's Memory: Defining the State
Every LangGraph agent is built around a central State object. This is the agent's memory, a single source of truth that is passed between nodes. For our translation agent, the state needs to track the conversation history, the languages, and the original text.
Here is a simplified version of our state definition:
# The agent's memory or "state"
class TranslateState(TypedDict):
"""
Tracks the full state of the translation conversation.
Attributes:
messages: The history of the conversation.
IMPORTANT: `add_messages` ensures new messages are appended, not replaced.
original_text: The initial text provided by the user.
source_language: The language to translate from (e.g., "English").
target_language: The language to translate to (e.g., "Spanish").
"""
messages: Annotated[list[BaseMessage], add_messages]
original_text: str
source_language: str
target_language: str
This simple dictionary holds all the information our agent needs to perform its job and maintain context from one turn to the next.
The Agent's Logic: A Tour of the Nodes
Our agent's workflow consists of three primary nodes that form a conversational loop.
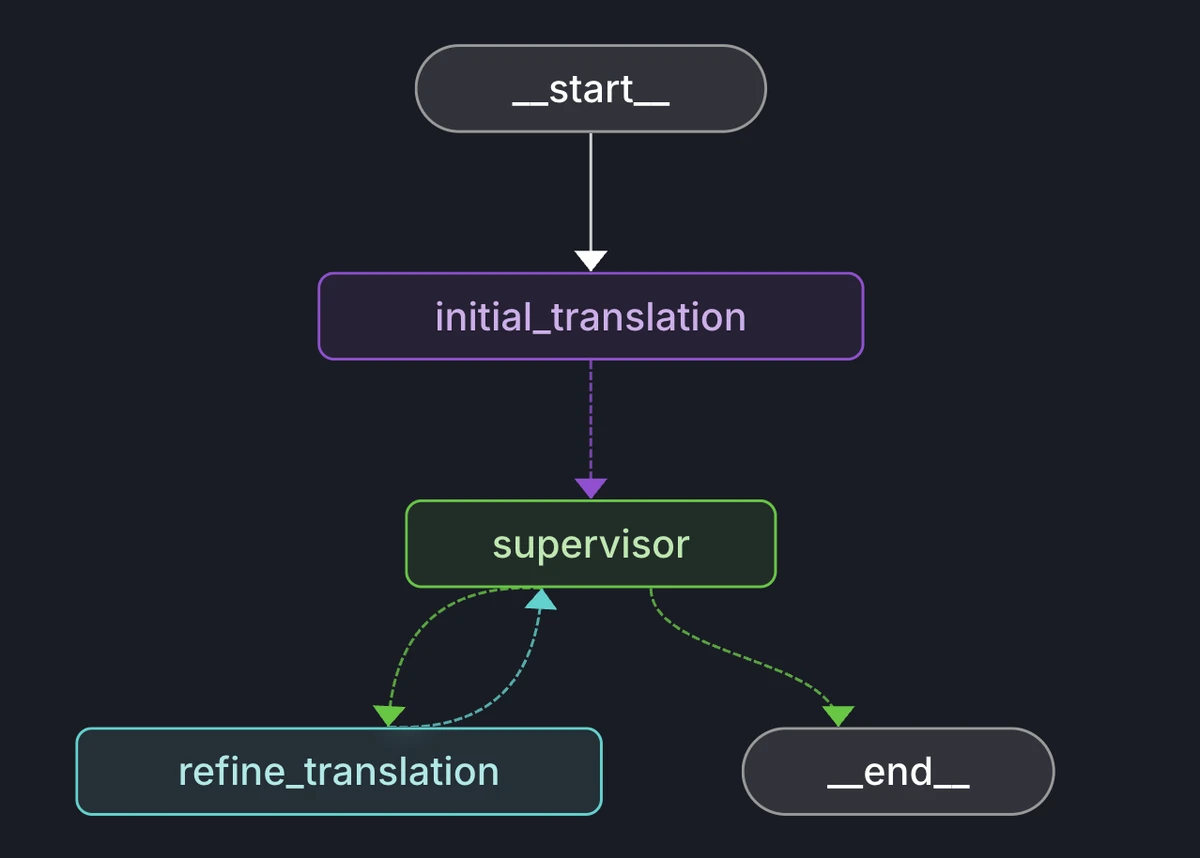
Diagram of the translateprompt.com LangGraph architecture, showing the initial_translation -> supervisor -> refine_translation loop
- initial_translation: This node kicks off the process. It takes the user's input text, fetches any relevant, user-specific glossaries or translation rules, and calls an LLM to generate the first translation.
# Simplified node for the first translation pass
def initial_translation(state: TranslateState):
"""Generates the first translation using context like glossaries and rules."""
user_input = state["messages"][-1].content
# Fetch user-specific glossaries and rules here...
prompt = create_initial_prompt(
text=user_input,
glossary=...,
rules=...
)
response = llm.invoke(prompt)
# Update the state with the AI's response and the original text
return {"messages": [AIMessage(content=response.content)], "original_text": user_input}
- supervisor: This is the most important node for user interaction. It acts as a gate, pausing the graph execution to return the latest translation to the user. It then waits for the user to provide feedback (e.g., "Change 'board meeting' to 'reunión directiva'"). This pause is achieved with LangGraph's built-in interrupt mechanism.
# Simplified supervisor node to wait for user feedback
def supervisor(state: TranslateState):
"""
Pauses the graph to wait for human input. This is what makes
the agent interactive.
"""
last_ai_message = state["messages"][-1].content
# The interrupt() call pauses execution and sends the message to the user.
# The graph will wait until the human provides feedback.
user_feedback = interrupt(last_ai_message)
# Once feedback is received, add it to the message history
return {"messages": [HumanMessage(content=user_feedback)]}
- refine_translation: Once the user provides feedback, the graph resumes and calls this node. It takes the previous translation and the user's correction, formats them into a new prompt, and asks the LLM to generate an improved version.
# Simplified node for refining the translation based on feedback
def refine_translation(state: TranslateState):
"""Takes user feedback and the previous translation to generate a new one."""
last_ai_message = state["messages"][-2]
user_feedback = state["messages"][-1]
prompt = create_refinement_prompt(
previous_translation=last_ai_message.content,
feedback=user_feedback.content
)
response = llm.invoke(prompt)
return {"messages": [AIMessage(content=response.content)]}
After this node runs, the control flow returns to the supervisor, creating the interactive loop.
Key Learnings from Building the Agent
Building this agent help me understand patterns that go beyond basic tutorials.
Learning #1: Prefer Command for Clearer Control Flow
In LangGraph, you can direct flow with conditional edges that check the agent's state. However, for a simple, deterministic loop like this, a much cleaner pattern is to have nodes return a Command. This explicitly tells the graph where to go next and what state to update.
# Example from the refine_translation node
def refine_translation(state: TranslateState):
# ... logic to get the refined translation ...
response = llm.invoke(prompt)
# Instead of relying on a separate edge function, we explicitly
# command the graph to update the state and go to the supervisor.
return Command(
goto="supervisor",
update={
"messages": [AIMessage(content=response.content)],
},
)
This approach makes the graph's logic much easier to follow and debug. The node itself declares its intent, rather than hiding the logic in a separate edge function.
Learning #2: Never Forget add_messages for Conversational State
This is a subtle but critical detail. When updating the messages list in our state, it's easy to accidentally overwrite the entire history. LangGraph provides a special accumulator, add_messages, to prevent this.
By defining our messages field in the state with Annotated[list[BaseMessage], add_messages], we ensure that any new messages returned from a node are appended to the existing list, not used as a replacement. This preserves the full conversational context, which is essential for the LLM to understand the refinement history. Without it, our agent would have no memory of past interactions.
The Bitter Insight: Removing nodes from an Agent for a Better User Experience
Early in development, I added a feature: after a user refines a translation, the agent should analyze the correction and suggest a new glossary term or rule to prevent that mistake in the future (e.g., "Should I always translate 'board meeting' as 'reunión directiva'?").
This was a great idea, but it was slow. The analysis LLM call could take several seconds. If I included this logic in the main refine_translation node, the user would have to stare at a loading spinner for 5-10 seconds just to get their corrected text back. This created a terrible user experience.
The solution was to decouple the slow, non-essential process from the fast, user-facing loop.
The architecture was split into two parts:
The Synchronous Loop: The initial -> supervisor -> refine loop runs quickly to give the user an immediate response.
The Asynchronous Background Job: The slow glossary suggestion logic is triggered after the response has been sent to the user, running completely in the background.
Implementing the Asynchronous, Non-Blocking System
This separation of concerns required two new components that live outside the main LangGraph agent.
The Background Job: check_glossary_updates
After the refine_translation graph node returns its result to the user, we make a "fire-and-forget" call to a background function. This function re-loads the conversation state and performs the slow analysis without blocking the user.
# This function is called ASYNCHRONOUSLY after the user gets their translation.
def check_glossary_updates(conversation_id: str):
"""
Analyzes the last interaction in the background to suggest glossary updates.
"""
# 1. Get the state from the checkpointer
state = get_graph_state(conversation_id)
translation, feedback, refined_translation = state["messages"][-3:]
# 2. Create a prompt for an LLM with tool-calling capabilities
prompt = create_glossary_suggestion_prompt(
translation_with_errors=translation.content,
user_feedback=feedback.content,
# ... other context ...
)
# 3. Invoke the LLM to see if it suggests a new rule or glossary term
tool_calling_llm = LLM_Service().bind_tools([RulesUpdate, GlossaryUpdate])
response = tool_calling_llm.invoke(prompt)
# 4. If suggestions are found, store them in a temporary cache
if response.tool_calls:
improvement_cache.add_calls(conversation_id, response.tool_calls)
The ImprovementToolCallsCache
Since the background job is disconnected from the user session, we need a place to store its findings. A simple in-memory cache, indexed by conversation_id, holds any suggestions until the user interface is ready to display them.
# A simple in-memory cache to hold suggestions from the background process.
class ImprovementToolCallsCache:
def __init__(self):
self._cache: Dict[str, List[Any]] = {}
def add_calls(self, conversation_id: str, tool_calls: List[Any]):
"""Add suggestions for a given conversation."""
if conversation_id not in self._cache:
self._cache[conversation_id] = []
self._cache[conversation_id].extend(tool_calls)
def get_calls(self, conversation_id: str) -> List[Any]:
"""Retrieve any pending suggestions."""
return self._cache.get(conversation_id, [])
# Global instance
improvement_cache = ImprovementToolCallsCache()
This architecture provides the best of both worlds: a fast, responsive user experience for the core translation task, and a powerful, intelligent analysis feature that works behind the scenes.
Conclusion: Balancing Complexity and Performance
Building translateprompt.com with LangGraph was a nice project to understand how to bring langgraph into real world projects. The three key takeaways were:
Use Command for explicit and readable control flow in your graph.
Always use the add_messages accumulator to correctly manage conversational memory.
Most importantly, for production-ready AI agents, ruthlessly identify slow processes and decouple them from the core user-facing loop. This asynchronous pattern is critical for delivering a fast and fluid user experience.
While this decoupled architecture adds some complexity, the performance and usability gains are more than worth it. It’s a powerful pattern for anyone building sophisticated, interactive AI agents.
I encourage you to explore these concepts further. You can find the full source code for this project on GitHub.
Check out the project on GitHub: https://github.com/bernatsampera/translateprompt